




Version [91424]
Dies ist eine alte Version von AdaBoost erstellt von Tobias Dietz am 2018-09-27 16:41:32.
AdaBoost
Idee
Die Idee hinter AdaBoost ist das erstellen mehrere Modelle mit der gleichen Hypothesenklasse als Grundlage. Dies bedeutet die Basis jedes Modells ist beispielsweise immer der gleiche Entscheidungsbaum mit den gleichen Parametern. Die verschiedenen Modelle werden dabei so trainiert, dass das jetzige Modell adaptiv auf den Fehler des vorherigen Modells reagiert. Am Ende bilden alle Modelle durch ihre Genauigkeit gewichtet eine Entscheidung. So versucht der Algorithmus, durch viele Iterationen, den Gesamtfehler zu minimieren und damit eine optimale Entscheidung zu treffen.
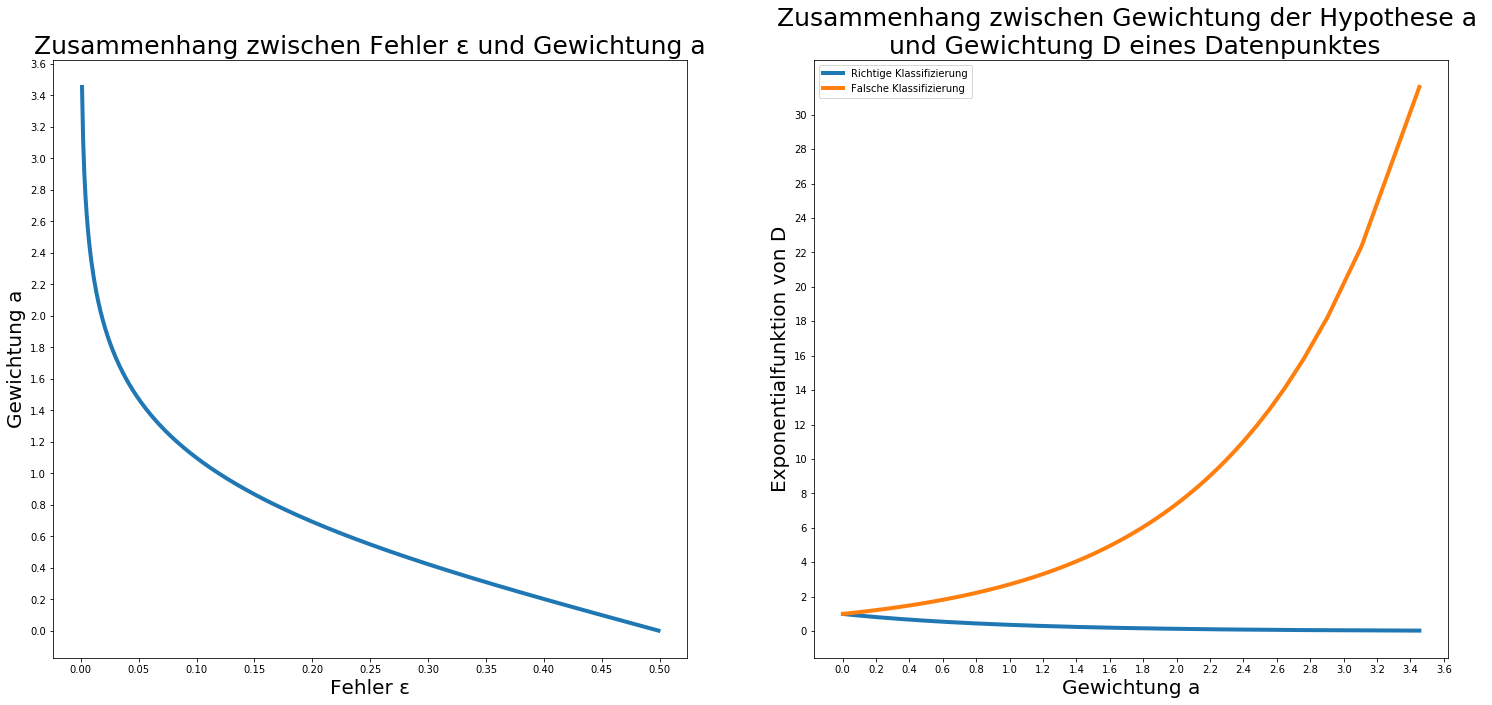
Algorithmus

Erklärungen
Ausblick
Der vorgestellte Algorithmus kann keine Multi-klassen-Probleme lösen. Hierfür gibt es jedoch Erweiterungen in welchen der Algorithmus trainiert wird. Hierfür wird die Funktion der Gewichtung angepasst und die Hypothese. Die Lösungsansätze verfolgen entweder one-versus-all oder one-versus-one Methoden zur Klassifikation.Ein beispiel hierfür ist der Samme.R Algorithmus. Genauere Erläuterungen hierzu finden sich in [] und [].
Literatur
[1] Freund Y., Schapire R. E. (1999): A Short Introduction to Boosting; AT & T Labs - Research[2] Schapire R. E. (unbekannt): Explaining AdaBoost; Princeton University, Dept. of Computer Science
[3] Zhou, Zhi-Hua (2012): Ensemble Methods: Foundations and Algorithms; Taylor & Francis Ltd
| File | Last modified | Size |
|---|---|---|
| AdaBoost.PNG | 2023-10-06 18:35 | 21Kb |
| Error_Verteilung.png | 2023-10-06 18:35 | 75Kb |
{kind=link}
{kind=link}
Diese Seite wurde noch nicht kommentiert.