




Version [22697]
Dies ist eine alte Version von ProzProg7ProzedurenFunktionen erstellt von RonnyGertler am 2013-03-28 18:22:52.
Prozedurale Programmierung - Kapitel 7 - Prozeduren und Funktionen
Inhalte von Dr. E. Nadobnyh
Ein Unterprogramm ist ein Teil eines Programms, welches:
1) einen Namen besitzt,
2) gestartet bzw. aufgerufen werden kann.
Synonyme: Funktion, Prozedur, Subroutine, Routine, benannter Block.
Unterprogramme dienen einer strukturierten Programmierung. Einige Ziele:
a) Zerlegung eines komplexen Gesamtproblems in Teilprobleme,
b) Wiederverwendung des Codes,
c)Lesbarkeit des Codes.
Programme bestehen typischerweise aus vielen kleinen und nicht aus wenigen großen Unterprogrammen.
Ablauf
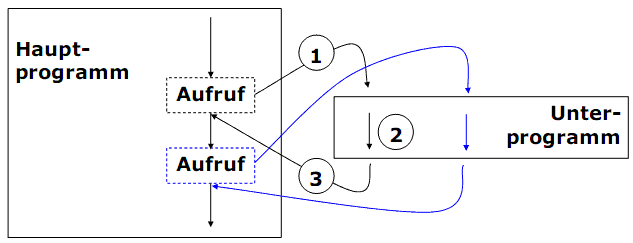
Der Ablauf eines Unterprogramms erfolgt in drei Schritten:
(1) Aufruf und Sprung zum Unterprogramm.
(2) Ausführung des Unterprogramms.
(3) Rückkehr zur Anweisung nach dem Aufruf.
Achtung: Begriffsverwirrung bei Ablauf vs. Aufruf!
Aufbau eines Unterprogramms
Bei der Definition wird ein Kopf und ein Rumpf festgelegt:
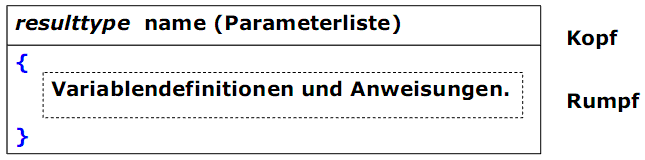
Der Kopf beschreibt alle Informationen, die zum Aufruf notwendig sind. Der Rumpf ist ein Block, der beim Aufruf ausgeführt wird.
Durch die Definition wird Speicherplatz belegt (für bestimmte Variablen und den Code). Unterprogrammen dürfen nur außerhalb jedes Blocks definiert werden.
Klassifikation

In der Sprache C/C++ werden Unterprogramme als Funktionen und Prozeduren als „void Funktionen“ bezeichnet.
Prozeduren
Eine Prozedur ist ein Unterprogramm, welches keinen Rückgabewert zurückliefert. Der Aufruf einer Prozedur ist deswegen eine Anweisung. Eine Prozedur hat kein resulttype. In C/C++ wird der resulttype der Prozedur mit dem fiktiven leeren Datentyp void spezifiziert.
Beispiel:
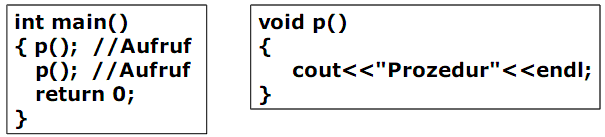
⇒ Demo 1. Prozedur
Funktionen
Eine Funktion ist ein Unterprogramm, welches ein Funktionsergebnis (Rückgabe, Resultat) zurückliefert.
Der Aufruf einer Funktion ist deswegen ein Ausdruck. Der Aufruf wird durch das Funktionsergebnis ersetzt.
In C/C++ wird das Funktionsergebnis mittels der Anweisung return explizit zurückgegeben. Dabei wird das Unterprogramm sofort verlassen.
Beispiel:

7.2. Datenaustausch zwischen Funktionen
Aufrufende und aufgerufene Funktionen müssen untereinander Daten austauschen können. Funktionen können Daten als Operanden erhalten und können Daten als Ergebnisse zurückliefern.
Es gibt verschiedene Mechanismen für den Datenaustausch (Datentransfer) zwischen Funktionen.
Austausch-Mechanismen könnte nach der Art von Schnittstellen und nach der Datenflussrichtung klassifiziert werden.
Es gibt drei Schnittstellen für den Datenaustausch zwischen Funktionen:
1) über globale Variablen,
2) über Parameter,
3) über das Funktionsergebnis.
Datenflussrichtung
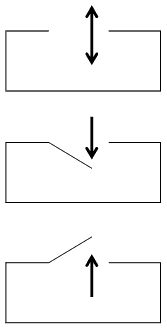
1. Der Datenfluss geht in beide Richtungen. Dabei können Operanden und Ergebnisse ausgetauscht werden.
2. Der Datenfluss geht nur in eine Funktion hinein. Dabei kann eine Funktion ein Operand übernehmen.
3. Der Datenfluss geht nur aus einer Funktion heraus. Dabei kann eine Funktion ein Ergebnis zurückliefern.
Analogie: Drehkreuz
Klassifizierung von Austausch-Mechanismen
|
Datenflussrichtung Schnittstelle |
In die Funktion hinein | Aus der Funktion heraus | In beide Richtungen |
| Globale Variablen | kein | kein | über globale Variablen |
| Parameter | call-by-value | kein | call-by- reference |
| call-by-reference auf const | per Zeiger | ||
| Funktionsergebnis | kein | per Wert | kein |
| per Referenz | |||
| per Zeiger |
In dieser Klassifikation sind 8 Austausch-Mechanismen vorgestellt.
Gültigkeitsbereiche
1. Mit Blöcken werden Gültigkeitsbereiche geschaffen.
2. Funktionen sind benannte Blöcke und mit ihnen werden auch Gültigkeitsbereiche geschaffen.
3. Der umfassende Gültigkeitsbereich wird als globaler Gültigkeitsbereich bezeichnet.
4. Funktionen dürfen nur außerhalb jedes Blocks, d.h. global definiert werden.
5. Funktionen können nicht in andere Funktionen geschachtelt werden. Sie können aber unbenannte Blöcke enthalten.
6. Unbenannte Blöcke dürfen nur in einer Funktion enthalten sein. Sie können aber ineinander geschachtelt werden.
Datenaustausch über globale Variablen
1. Variablen werden als lokal/global bezeichnet, wenn sie innerhalb/außerhalb eines Blocks definiert sind.
2. In geschachtelten Blöcken haben innere/äußere Blöcke die inneren/äußeren lokalen Variablen.
3. Innere Blöcke haben den Zugriff auf die Variablen der äußeren Blöcke. Mehrere innere Blöcke können die äußeren Variablen gemeinsam für den Datenaustausch verwenden.
4. Die globalen Variablen sind äußere Variablen für die globalen Funktionen und können als gemeinsame Variablen für den Datenaustausch verwendet werden.
Beispiel:
int a;
void f(){ cout<<a; }
int main() { a=5; f(); return 0;}
void f(){ cout<<a; }
int main() { a=5; f(); return 0;}
5. Namen, die lokal vereinbart wurden, sind außerhalb der Funktion unbekannt. Somit können verschiedene Funktionen Variablen gleichen Namens verwenden, ohne dass ein Konflikt entsteht.
6. Globale Variablen werden durch lokale Variablen gleichen Namens überdeckt. Bei Verlassen des inneren Blocks ist die äußere Variable wieder sichtbar.
Eine globale Variable besitzt zwar eine Lebensdauer, die vom Programmbegin bis zum Programmende reicht, der Gültigkeitsbereich kann hingegen "Löcher" haben.
7. Nachteil von globalen Variablen: Jede Funktion hat eine Zugriffsmöglichkeit auf mehrere (alle) globale Variablen. Es besteht die Gefahr unbeabsichtigter Veränderungen globaler Werte.
⇒ Demo 3. Überdeckung
7.3. Parameter
Parameter sind Daten, die beim Aufruf vom Aufrufer zu aufgerufener Funktion automatisch übergeben werden.
Die wichtige Besonderheit des Datenaustausches über Parameter ist der automatische Datentransfer vom Aufrufer zur aufgerufenen Funktion.
Die Begriffe Parameter und Argument sind im C-Standard folgendermaßen definiert:
1) Parameter oder formaler Parameter wird bei einer Funktionsdeklaration (bzw. Definition) verwendet und
2) Argument oder aktueller Parameter bei einem Funktionsaufruf.
Ein formaler Parameter wird als Platzhalter für den aktuellen Parameter bezeichnet.
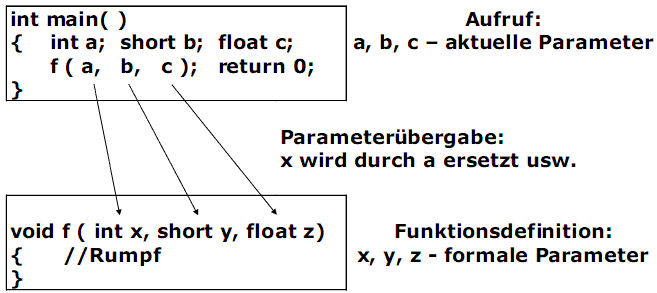
Parameterliste
Alle Parameter einer Funktion sind in einer Parameterliste zusammengestellt.
Eine Parameterliste einer parameterlosen Funktion ist entweder leer oder besteht nur aus dem Datentyp void. Die Liste aktueller Parameter muß mit der Liste der formalen Parameter nach Anzahl, Reihenfolge und Typ der Parameter übereinstimmen.
Beim Aufruf einer Funktion muss normalerweise für jeden formalen Parameter ein Argument eingesetzt werden.
Analogie: Die Parameterlisten mit den formalen Parametern und die Parameterliste mit den aktuellen Parameter müssen zusammenpassen wie Stecker und Kupplung einer elektrischen Verbindung.
Übereinstimmung. Beispiel
Aufruf
Die Verwendung einer Funktion wird allgemein auch Funktions-Aufruf genannt. Ein Aufruf ist eine komplexe Anweisung und besteht aus einigen Schritten:
1. Alle Argumente werden ausgewertet, z.B. die Argumente können Ausdrücke sein.
2. Zusammengehörige Parameter werden konvertiert, wenn sie verschiedene Typen besitzen. Dafür müssen sie Typkompatibel sein.
3. Die aktuellen Parameter werden an die Funktion übergeben.
4. Es folgt eine Vorbereitung der Rückkehr zum Aufrufer.
5. Es folgt ein Sprung (Übergang, Kontrollübergabe) zur aufgerufenen Funktion.
call-by-value
Bei der Wertübergabe (call by value) wird an die Funktion Kopien der aktuellen Parameter des Aufrufers übergeben.
Der Datenfluss geht nur in die Funktion hinein. Deswegen wird ein solcher Parameter als Eingangsparameter (IN-Parameter) bezeichnet.
Vorteil: Die Funktion kann den aktuellen Parameter des Aufrufers nicht verändern.
Nachteil: Das Kopieren des aktuellen Parameters kann mit einem größeren Zeitaufwand verbunden sein, wenn dieser Parameter vom „großen“ Datentyp ist.
Beispiel:
int main()
{ int a=5; f(a);
return 0;
}
void f(int a1)
{ cout<<a1;
}
{ int a=5; f(a);
return 0;
}
void f(int a1)
{ cout<<a1;
}
⇒ Demo 4.
CategoryProzProg
Diese Seite wurde noch nicht kommentiert.